

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向地震应急的自媒体信息挖掘模型
[苏晓慧1)  , 邹再超
, 邹再超2) , 苏伟2, 3) , 李林2) , 刘峻明2, 3) , 张晓东2, 3), * ]
, 邹再超]
|
|


〔作者简介〕 苏晓慧, 女, 1985年生, 2013年于中国农业大学获农业信息化技术专业博士学位, 讲师, 主要研究方向为空间信息技术及其应用, 电话: 010-62338246, E-mail: suxhui@bjfu.edu.cn。
从近几年发生的特大自然灾害事件中可以发现, 社交媒体平台正日益成为普通公众及时发布和获取灾情信息的最主要、 最便捷的新途径, 在这类平台获取的数据中隐藏了大量记录灾情现状的文字、 图片等信息。 文中首先对海量的历史灾情数据进行统计分析, 构建了面向地震应急的信息类别体系和危急度评价体系; 基于此训练了用于信息分类的朴素贝叶斯模型, 模型的准确率为73.6%; 同时采用机器学习模型和语义计算模型这种特征融合的分类方法, 对灾情信息的危急度进行评价, 评价模型的准确率为89.2%。 该模型能够在震后实时地对自媒体中出现的灾情信息进行爬取、 分类和评价等操作, 可从海量的自媒体信息中挖掘出少量危急又重要的信息, 以辅助震后的灾情研判和精准救援。 文中最后以2017年8月8日九寨沟地震事件为例, 从地震烈度速报、 震后精准救援2个角度对挖掘数据的可用性进行了研究分析。
From the events of catastrophic natural disasters that have occurred in recent years, it can be found that social media platforms are increasingly becoming the most important and most convenient way for the general public to timely release and obtain information on disasters. The information obtained from such platforms contains a large amount of information in the form of texts, pictures, etc. that record the current situation of the disaster. And it also has characteristics of high efficiency and high spatial distribution to serve the rapid emergency after the earthquake. In this paper, we firstly make a statistical analysis of 32 689 pieces of historical disaster data acquired from 5 earthquakes with obvious characteristics, such as post-earthquake disaster events, user's expression habits and so on, and adopts cross-validation method. Then information classification system which includes seven first-level categories and more than 50 second-level categories is constructed. The information classification system and evaluation system of crisis degree for post-earthquake emergency response are constructed both using cross-validation method. The former is referred to the thought of existing classification basis and the experience knowledge of several emergency experts. Based on the five indicators of subject word, action word, degree word, time and position measurement, an evaluation system of critically with four levels of severity, moderate intensity, mildness and others was constructed. Considering the sparse features of self-media information and the large difference in the number of training sets, a naive Bayes model for information classification is trained based on the classification system and evaluation system. Its accuracy rate is 73.6%. At the same time, the classification method of feature fusion of machine learning model and semantic calculation model is used to evaluate the criticality of the disaster information. The accuracy rate of the evaluation model is 89.2%, higher than 85.2% of the semantic computing model and 77% of the naive Bayesian model. The evaluation model has combined the advantages of semantic computing method which can evaluate all index features with machine learning method which has high classification efficiency and accuracy. The thresholds for classification between mild and moderate intensity, moderate intensity and severe intensity were 15.2 and 27.39. The model realized in this paper can crawl, classify and evaluate the disaster information in the media in real time after an earthquake, and realizes mining of a small amount of critical and important information from the massive self-media information, thus, to assist in earthquake intensity rapid reporting and accurate rescue. Finally, taking the Jiuzhaigou earthquake on August 8, 2017 as an example, 17 432 pieces of data were crawled in real time within 48 hours after the earthquake. At the same time, based on ArcGIS, the mining information is visualized in time and space, and the availability of the data is evaluated from two perspectives of earthquake intensity quick reporting and accurate rescue after the earthquake. The disaster information of Jiuzhaigou County in the earthquake area is obviously more than that of the non-earthquake area in terms of quantity and emergency degree. The results show that the self-media information with high spatial distribution can effectively find the severer disaster grade area after the earthquake, shorten the time of earthquake intensity prediction, effectively classify and extract information, provide real-time information for precise rescue, and improve the efficiency of emergency response after the earthquake.
中国是世界上地震灾害活动最频繁和遭受地震损害最严重的国家之一。 据中国地震台网数据显示, 近5a以来中国发生的5级以上地震就高达40余次, 其中共有18次发生在四川等西部偏远地区。 在这些地区发生的地震大都暴露出灾害预警能力、 信息收集能力及舆情控制能力等需进一步加强的问题, 这也直接反映了传统灾情信息获取、 挖掘和反馈能力与互联网媒体相比都存在明显滞后, 无法满足地震应急时对信息时效性、 精准性的需求。
相较于通过航空航天遥感、 地面监测站等途径获取的数据, 来源于社交媒体平台的地震应急信息所具有的潜在优势引起了广泛的关注。 其主要的优势包括: 1)从这类平台获取的信息具有强交互性、 高时效性和高空间分布性等特点; 2)传统灾害信息, 如影像数据和地面监测站数据等, 其收集往往受天气、 空间所制约, 而来源于社交媒体的信息则突破了这种局限性; 3)社会公众对于借助这些平台关注自身安全问题的认可度越来越高, 并自发地参与到社会的治理中去。 因此, 有效地挖掘这类信息可集民众之智, 实现全民救灾, 产生最大的救灾效果。
地震应急最突出的特点是时间紧迫且事关重大, 要求在最短的时间内完成灾情研判、 拟定救灾方案及部署救援力量等。 而灾情信息的快速获取, 对地震应急工作的有序开展起着决定性的作用(聂高众等, 2012)。 虽然目前已有很多学者基于自媒体信息在灾情时空演变、 场景重构及舆情分析等领域开展了大量研究, 但针对震后灾情速判、 应急救援等开展快速应用的研究尚不足。 如Crooks等(2013)依据震后自媒体信息在不同地理空间中出现的速度和频度, 来判断灾情的严峻性和受灾范围。 还有一些学者在以上时空数据挖掘分析的基础上, 开展了与图片、 短视频等信息结合进行灾情场景重构的研究, 进一步服务于灾后的应急救援和指挥决策中(Guan et al., 2014; Herfort et al., 2015)。 将自媒体信息用于辅助灾害的应急管理、 增强场景意识的难点在于信息的快速挖掘和语义分析, 这也是当前许多学者研究的重点。 Vieweg等(2010)定义了1个完整的分类体系来编码灾情信息, 其中包括警示类、 人员伤亡类、 灾情求助类和信息统计类等。 更多的研究则是基于森林火灾、 飓风、 泥石流等某一特定灾情事件, 结合应急需求对自媒体灾情信息进行分类编码, 基于此挖掘灾情信息所表现的时空变化特征与灾害的实际影响区域、 演变趋势等的相关性(Herfort et al., 2015; Huang et al., 2015)。 而在语义分析方法的选择上, 目前研究较多的是基于自然语言处理技术, 即通过训练朴素贝叶斯、 支持向量机、 神经网络等机器学习模型来进行中文文本的分类(刘志明等, 2012); 而在某些特定的研究领域也会采用传统的熵权模型, 即通过匹配文本中不同的特征词来进行赋权分析(孙建旺等, 2014)。
虽然目前针对自媒体灾情信息的研究已经非常多, 但已有研究构建的类别体系大都缺乏对震后快速应急和已有国家应急信息分类标准的考虑; 同时没有针对灾民借助自媒体平台求助或发布重大灾情类信息的习惯, 开展重大灾情事件快速挖掘和精准救援的研究。 本文将基于此开展接下来的研究。
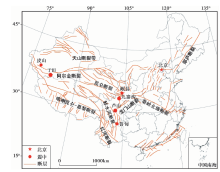
本文中的案例数据全部来源于中国最流行的微博网站— — 新浪微博, 它是中国最大的互联网内容提供者和分发者之一。 研究借助于Weibo API, 基于主题词爬虫的方式获取了5次具有代表性的地震事件震后3d的数据共32 680条。 这5次地震分布在中国地震频发的中西部地区(图1), 对应的详情信息(表1)来源于中国地震台网。 从这5次地震中获取的灾情信息不仅数量多, 而且震后灾情事件、 用户的表达习惯等特征明显且覆盖全面, 下面将基于这些数据构建分类训练集和危急度评价的指标体系。
 | 图 1 5次地震事件空间分布图(断层数据来自嵇少丞, 2009)Fig. 1 Spatial distribution of five seismic events(faults data are from JI Shao-cheng, 2009). |
| 表1 5次地震事件详情 Table1 Details of the five earthquake events |
目前已有的地震应急信息分类体系涉及的行业、 要素和维度非常宽泛, 并不适用于自媒体信息, 更不能满足震后快速、 精准应急的需求。 如何通过语义分析等技术手段把隐含在信息中的灾情类别快速地挖掘出来, 真正发挥其在灾情速判、 指挥决策中的应用价值, 是本研究构建地震应急信息分类体系和模型的目标导向。
在类别体系建立的过程中, 以采集的5次灾情数据为基础, 采用交叉验证的方法(Qu et al., 2011), 即通过自下而上的方式, 从这些案例数据中提取特征并确定主题; 再进一步采用自上而下的方式, 参考已有分类依据的思想以及多位应急专家的经验知识, 对分类主题进行评价优化, 最终构建了满足地震应急需求的类别体系, 依据主题共划分为7个一级类别和50多个二级类别(表2)。
| 表2 地震应急信息类别 Table2 Classification system of earthquake emergency information |
通过基本的信息分类, 能够有效地把具有相同主题特征的信息进行归类, 但在震后并不能快速地将少量特别危急的信息挖掘出来, 也就无法满足震后应急时紧急性、 精准性的需求。 而危急度评价就是通过分析不同危急程度的信息所具有的特征, 来构建危急度评价的指标体系和评价模型, 实现震后对危急事件的精准、 快速挖掘。
危急度评价类似于文本的情感分析, 评价指标、 等级、 模型比文本分类更为复杂, 而评价体系构建是最为关键的一步。 研究中构建的危急度评价体系由评价等级、 指标和主题词库这3部分内容构成, 在评价等级构建的过程中, 基于已有国家地震应急预案和突发事件应对法中的响应级别, 结合应急信息中所表达事件的危急特征, 构建了程度等级为4级的评价标准: 剧烈、 中强、 轻微和其它, 其中其它类别是危急程度为0的一类信息。 另外依据微博信息的内容格式和灾情的时空特征, 将评价指标划分为主体词、 行为词、 程度词、 时间和位置度量。 最后采用交叉验证的方法, 以人工标注的方式从5次地震的灾情数据中提取相应的主题词, 并构建危急度评价的主题词库。 其中, 位置度量依据从文本中语义提取位置的精细度和震害影响的范围程度确定, 当位于区县时, 位置较为精细, 危急度评价为剧烈, 以此类推; 时间度量依据救援的最佳时间节点和自媒体中不同时间段应急信息类别的变化而确定, 在信息爆发期即受灾24h内为剧烈, 在信息活跃期即黄金救灾72h内为中强, 在信息消匿期即受灾5d内为轻微。 表3列举了评价指标为主体词、 行为词和程度词的部分主题词。
| 表3 危急度评价体系表 Table3 Evaluation system of crisis degree |
研究中综合考虑自媒体信息存在特征稀疏、 训练集间数量差别大等问题, 选择了有着坚实数学基础、 稳定分类效率的朴素贝叶斯分类模型(Kim et al., 2006)作为文本分类的机器学习模型。 针对贝叶斯算法对条件概率分布作出独立性假设的前提, 即假设各个维度的特征x1, x2, …, xn相互独立, 并结合文本中各特征xi对类别标签yk的占比关系进行了条件概率转化, 最终构建的朴素贝叶斯分类模型可表示为
式中, Ryk代表文本x在各类别yk中的最大概率值, 同时也是文本x最终输出的类别标签; 分子中P(yk) 是先验概率, 可根据训练集计算得出, 而分母是根据全概率公式分解P(x)所得。
在训练贝叶斯模型的过程中, 为了保证其可靠稳定性并提高模型的泛化能力, 采用10折交叉验证(Fushiki, 2011)的方式来训练, 经过多次模型优化和训练集完善, 最终生成的稳定分类模型的准确率、 召回率、 F值分别为73.6%、 69.7%、 69.8%, 基本能满足震后应急时对信息准确挖掘的需求。 从模型输出的混淆矩阵中可以发现(图2), 次生灾害、 重大工程和生命线这3个类别的准确率较低, 究其原因是构建这几类训练集的信息数量少所导致。 同时, 通过分析错分的数据可以发现, 这些信息大部分都表达了多重内容, 如: “ 救援队一行8人抵达宝兴县, 在徒步进入太平镇后, 救援队突遭山体滑坡, 目前与总部失去联系” , 这条信息的预测类别为次生灾害类, 实际分为抢险救灾类, 实则隐含了双重内容。
 | 图 2 模型精度评价的混淆矩阵Fig. 2 Confusion matrix for model accuracy evaluation. |
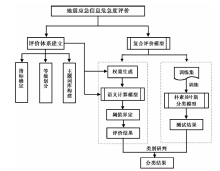
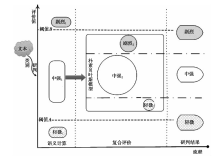
危急度评价类似于文本的情感分析, 其不仅仅是一种文本分类, 而是更倾向于对用户情感的理解。 传统的基于词典的语义计算方法能综合单条信息中的所有指标特征进行评价, 但也存在不能识别未登录词、 转折词等缺陷; 而机器学习模型虽然分类效率和准确率都较高, 但对特征稀疏的微博短文本的情感理解能力差, 表现的分类效果也不稳定。 本研究鉴于两者各自的优缺点, 构建了一个机器学习和语义计算特征融合的复合评价模型, 用于震后灾情信息危急度的评价, 其技术原理如图 3所示。
 | 图 3 危急度评价原理图Fig. 3 Schematic diagram of criticality evaluation. |
(1)模型建立
研究基于构建的危急度评价体系, 建立了一套用于灾情信息危急度评价的语义计算模型(式(2))。 模型将文本的语义特征作为评价主体, 并综合考虑微博发布的时空等因素, 建立了能近似表达灾情事件危急度特征的模型。 式中, s、 a、 l代表文本中匹配到的评价指标, 分别对应主体词、 行为词和程度词, i、 j、 k、 u、 v代表评价等级, 而K、 T、 L分别代表主题词、 时间和位置度量的权重值, N则是所对应的同一类型的主题词数量, 最后通过累加求和得到最终的危急度评价值S。
(2)权重生成
权重的准确生成对提高模型评价结果的准确性起着至关重要的作用。 文中结合评价等级和指标间的层级关系, 选择了层次分析法(AHP)来生成主题词的权重。
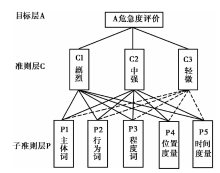
AHP在干旱、 泥石流等灾害致灾因子的评价中广泛应用, 其基本思想是把一个复杂的评价问题分解为各个组成因素, 并形成一个有序的递阶层次结构, 然后通过两两比较的方式, 并综合人的判断来确定层次中诸因素的相对重要性(Nefeslioglu et al., 2013; Palchaudhuri et al., 2016)。 文中基于危急度评价的指标体系构建了危急度评价的层次模型(图4), 同时结合灾情信息中各指标间的相对重要性和应急专家积累的先验知识, 采用了1(无差异)~9(极端重要)的比例标度进行因素间的比较打分, 最终构造了准则层C、 P的判断矩阵(表4, 5), 判断矩阵的最大特征根λ max分别为3.02和5.32。 经多次赋值计算和一致性检验, 生成的准则层C、 P的一致性指标CI分别为0.01和0.08, 接近于0, 且检验系数CR分别为0.019和0.07, 均< 0.1, 说明构造的判断矩阵具有满意一致性。
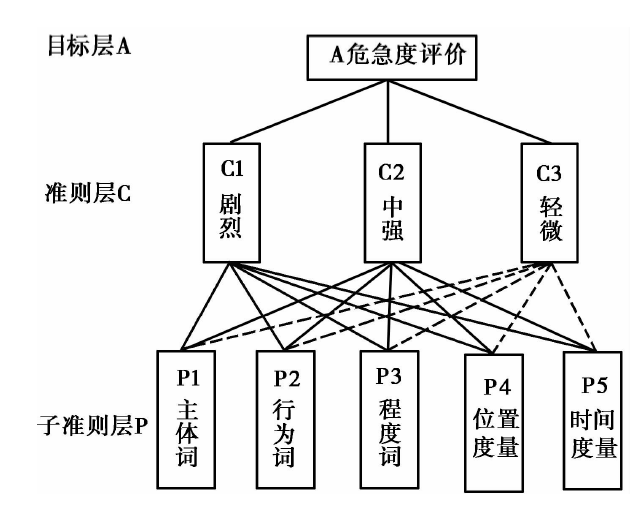 | 图 4 评价体系的AHP模型Fig. 4 AHP model of evaluation system. |
| 表4 准则层C的判断矩阵 Table4 Judgement matrix of the criterion layer |
| 表5 子准则层P的判断矩阵 Table5 Judgement matrix of the subcriterion layer |
(3)模型验证
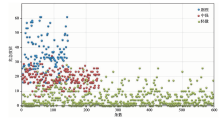
为保证模型的训练效果最优, 将历次地震事件中没有危急程度的一类信息剔除, 并按照危急等级的比例分布选取1 000条数据作为测试集, 来验证语义计算模型和权重值的有效性。 基于Python语言实现的模型, 生成了1 000条数据的危急度评价值, 其分布如图 5所示。 其中横坐标代表信息数量, 纵坐标代表评价值扩大100倍后的结果分布, 而蓝、 红、 绿点则是事先由人工标注的危急度测试集类别。
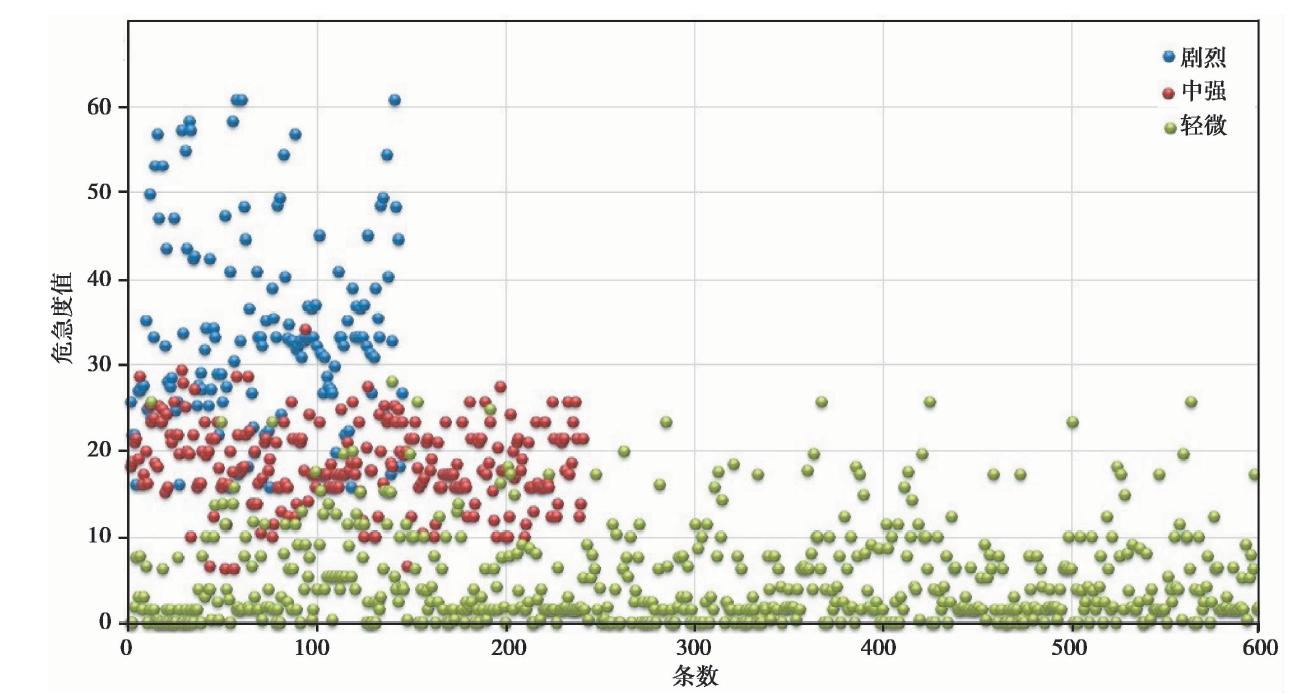 | 图 5 测试集计算值分布图Fig. 5 Distribution diagram of the test set calculated value. |
基于坐标系中的数据可以明显发现一些规律, 如在阈值> 30和< 10的范围内可以实现对剧烈和轻微类信息的有效分类, 而在区间[10, 30], 即中强区间的信息分类效果较差。 通过分析数据发现, 在中强区间散布的剧烈类信息存在未登录词或特征稀疏等问题, 导致评价值较小; 而轻微类信息则因语义计算模型不能准确理解转折词、 否定词等弊端, 评价值较高。 基于这些特征, 下面将在研究中通过确定最优阈值和构建复合评价模型的方式, 提高危急度评价结果的准确率。
(1)建立模型
在类别研判的过程中, 针对中强区间范围的信息语义计算结果误差较大的问题, 采用复合机器学习模型的方式来提高分类精度。 信息分类过程需要经过2个步骤, 为了区分不同阶段得到的分类结果, 此处采用下标的方式表示, 如下标为1即语义计算阈值判断得到的结果, 下标为2则为经过复合评价得到的结果。 首先在语义计算阶段确定中强与轻微、 剧烈间的阈值A和B, 保证剧烈和轻微类信息的准确率, 此时得到的数据集按照阈值A和B分为剧烈1、 中强1和轻微1 3大类, 然后基于此结合贝叶斯分类模型的分类结果对中强区间散布的信息进行研判输出。 在这一区间, 如果分类结果为中强类(中强2), 则研判一致, 直接输出; 如果为剧烈类(剧烈2), 基于灾情悲观法(王夏林, 2013)的原则输出为剧烈类; 如果为轻微类(轻微2), 由于构成该类型的训练集较多, 表现的分类效果好, 同样可直接输出为轻微类。 经综合研判后, 可作为最终的危急度评价结果, 其原理如图 6所示。
 | 图 6 混合评价模型原理图Fig. 6 Schematic diagram of mixed evaluation model. |
(2)确定阈值
保证复合评价模型结果最优的关键是阈值A和B的确定。研究采用定量比较分析的方法, 即将纯净度(图5中剧烈和轻微区间内正确分类的信息数量占该区间信息总量的百分比)作为定量指标和评价基准, 以确定阈值A、B和该阈值所对应的语义计算模型中强区间和整体、 复合评价模型的准确率(表6)。
| 表6 定量统计确定阈值表 Table6 The threshold table from quantitative statistics |
由于危急度计算值呈间断性分布, 且阈值A、 B间跨度小, 因此研究取2%作为纯净度变化的滑动值, 对该1 000条数据的计算值进行统计分析, 并得到表6所示的结果。 表中语义计算模型的准确率虽普遍高达80%以上, 但准确率并非随着纯净度的增加而增加。 而是在纯净度为91%时出现拐点, 当纯净度在83%~91%之间逐渐增加时, 语义准确率和复合评价准确率均呈现递增的趋势; 但当纯净度在91%~95%之间逐渐增加时, 语义准确率和复合评价准确率则呈现递减的趋势, 故当分类阈值为15.2和27.39时模型表现的分类效果整体最佳, 因此将其作为模型的中强与轻微、 剧烈间的界限值。
通过以上的模型建立、 权重生成和阈值界定, 最终构建了满足精度要求的复合评价模型, 模型对危急度评价的准确率达到89.2%, 远高于语义计算模型的85.2%和朴素贝叶斯模型的77%。
2017年8月8日21时19分, 四川省九寨沟县突发7.0级地震, 由于地震发生在夜间, 正值旅游旺季, 且震中距5.1km范围内平均海拔约3 827m, 极易发生滑坡等次生灾害, 因此, 快速获取灾情信息并进行研判和响应刻不容缓。 在地震发生后迅速启动本系统, 在3h内共实时爬取到涉及内容位于震区附近的微博数据571条, 同时完成了数据的分类、 危急度评价和位置信息提取等操作。 系统中的位置提取功能是基于中国科学院计算技术研究所研发的NLPIR(刘克强, 2009)分词模块实现的, 该模块在中文分词、 命名实体识别等语义分析中优势明显。
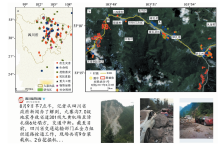
研究借助ArcGIS对提取的位置信息进行空间可视化后发现, 信息的数量和危急度计算值在空间分布上与震中距离呈负相关性。 据此采用克里金插值法对计算值进行插值分析, 采用热点分析法生成数据分布的热度图(图7a)。 从图中热度值和危急度值的空间分布可以发现, 震中附近的热点高值区域大致位于中国地震局在震后第4天绘制的烈度等级Ⅷ 度区内部(图7b); 而另一处位于九寨沟县城附近的热点高值区域, 则是由于县城自媒体用户较多, 相应生成热点高值。 同时危急度对应剧烈(22~25)和中强(15.5~21.9)区间所生成的插值区域大致位于烈度等级Ⅶ 、 Ⅵ 度区内部。 基于以上数据的探索性分析结果可以发现, 在烈度速报中利用具有高空间分布性的自媒体信息, 能够在震后有效地发现灾情较严重的区域, 并大大缩短灾后灾情严重区域的预测时间, 提升震后应急的效率。
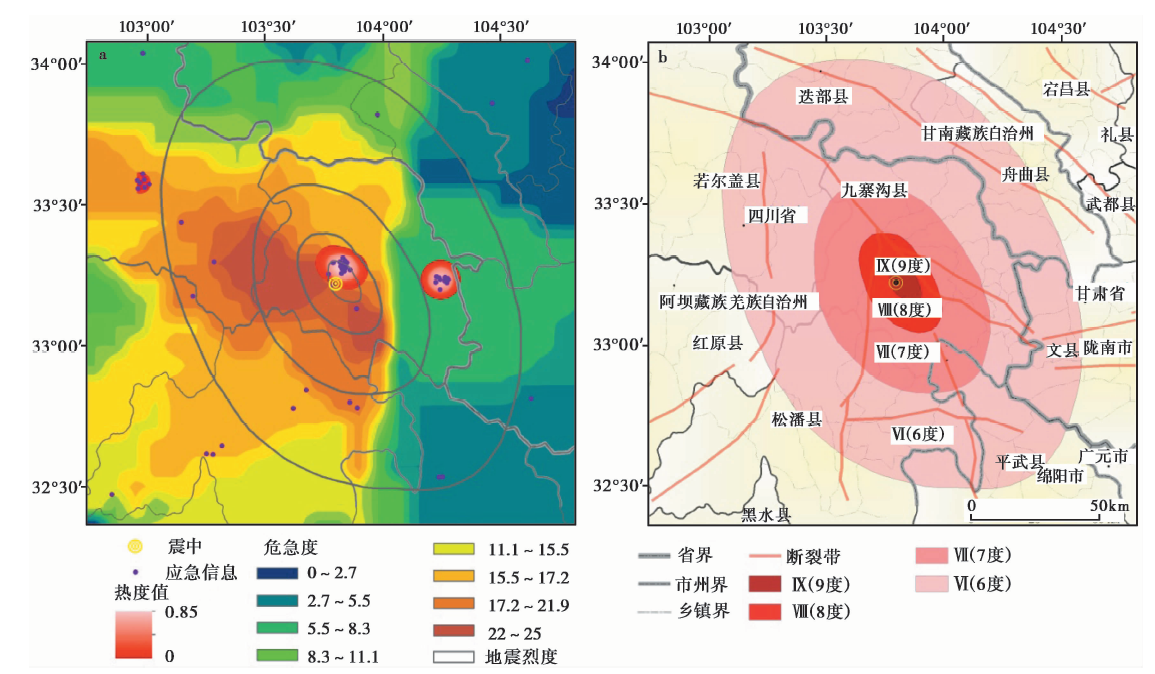 | 图 7 地震烈度速报图 a 微博数据热度分析图; b 九寨沟7.0级地震烈度图Fig. 7 Seismic intensity quick report thematic map. |
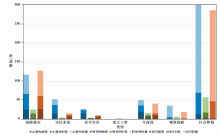
震后48h内共实时爬取到数据17 432条, 经去重除噪、 语义分析处理后, 筛选出1 479条与地震应急相关的信息, 信息的数目和类别特征如图8、 表7所示。 同时在图9a中以空间可视化的形式展示了信息的类型和空间分布, 并将图中绿色区域, 即九寨沟县301省道的部分区域作为研究对象, 从震后精准救援的角度对数据的可用性进行研究。
 | 图 8 地震应急信息分类统计图Fig. 8 Classification chart of earthquake emergency information. |
| 表7 地震应急信息分类统计表(单位: 条) Table7 Classification table of earthquake emergency information |
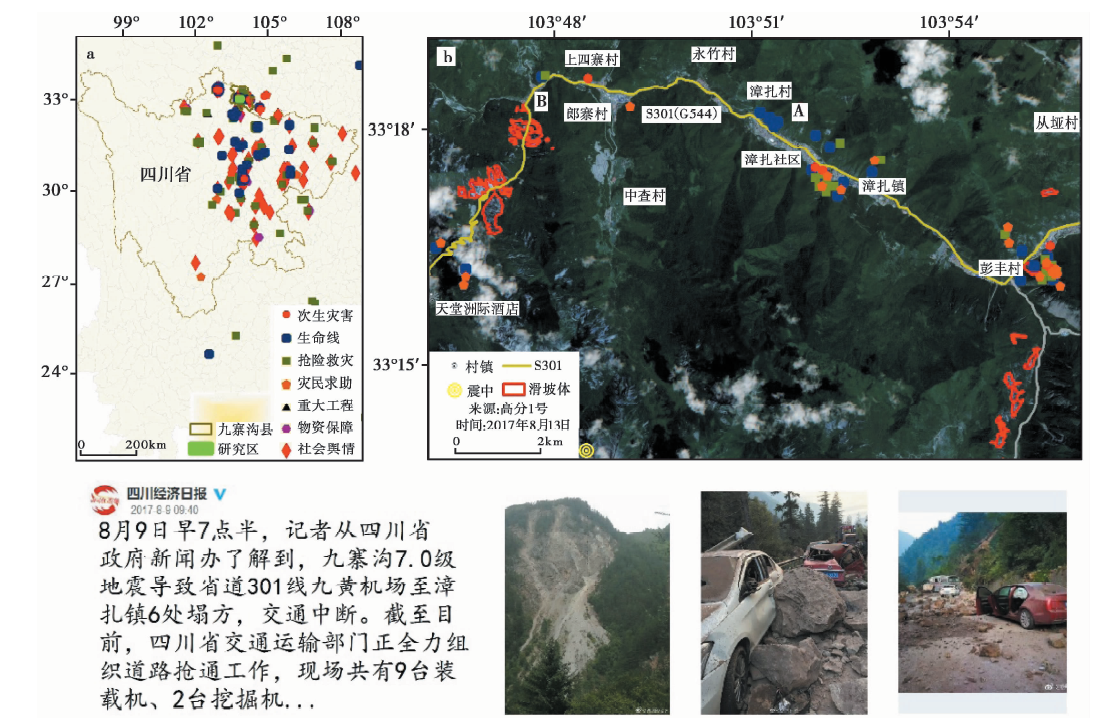 | 图 9 精准救援专题图Fig. 9 Precise rescue thematic map. |
深入分析图表中数据发现, 所采集的位于震区九寨沟县的灾情类信息, 无论从数量上还是危急程度上明显多于非震区, 说明文中的研究方法能有效地对信息进行分类和位置提取。 而在四川省其他城市抢险救灾类信息数量较多, 是由于震后有大批附近市县的救援力量开始迅速集结, 并发布了相关信息。 而在四川省内人口越密集、 经济越发达的地区对震情的关注程度就越高, 发布的相关舆情信息数量也就越多。
在研究区(图9b)中包含的元素有高分一号影像数据、 提取的滑坡体数据、 村落分布以及191条位于该区域的地震应急信息。 在精准救援中, 以图9b中A处的生命线破坏类信息为例, 虽然基于自然语言处理方法提取的位置A与真实位置B存在约5km的偏差, 但依据文字、 图片信息可以进一步精确定位。 A处信息爬取的时间为8月9日9时40分, 判断的类别为生命线破坏类, 危急度为剧烈, 信息中的详情内容及相关图片如图 9所示。 通过融合后的多源灾情信息可结合信息中的文字、 图片等在微观尺度判断滑坡体对生命线的破坏程度和人员伤亡情况, 并进行精准救援, 如在A处5km范围内共有17条隐含抢险救灾队伍的信息, 可以指挥调度进行快速精准救援。 其次, 又可结合影像中的滑坡体、 生命线破坏等情况从宏观尺度提取数据, 判断自媒体灾情信息的真实位置, 并基于爬取到的信息对区域内的资源进行指挥调度, 如在该区域经实时挖掘和人工判读后, 生命线破坏、 次生灾害等类别灾情信息共44条, 而救灾保障类信息仅20条, 从侧面反映了救灾需求远大于供给的情况, 需要进一步增加救灾队伍和物资资源的配置与调度。
以往灾情信息获取能力滞后, 导致震后快速应急能力不足。 本研究基于自媒体信息的高时效性、 高空间分布性等独特优势, 构建了满足地震应急需求的信息分类体系和符合自媒体灾情信息特点的危急度评价体系。 在此基础上基于Python语言实现的贝叶斯分类模型, 准确率达到73.6%; 提出的危急度复合评价模型准确率达到89.2%, 基本满足震后应急时对信息快速挖掘的需求。
研究成果在九寨沟地震事件中的应用实例证明, 实时爬取、 快速挖掘、 准确定位的自媒体灾情信息可以为灾情速判、 精准救援等提供多方位的数据支持。 但受历史有效数据量的限制, 研究中还存在构建的分类训练集数量少且分布不均等不足, 模型的鲁棒性仍有待提高, 可在今后的灾情事件中补充数据集, 对分类体系和评价模型进行验证优化, 并针对特大型地震中灾情信息的时空变化规律和应急救援模型的建立展开研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|