地震地质 ›› 2022, Vol. 44 ›› Issue (6): 1615-1633.DOI: 10.3969/j.issn.0253-4967.2022.06.015
张苏祥1)( ), 盛书中1),*(), 席彪2), 房立华3), 吕坚4), 王甘娇4), 张潇1)
), 盛书中1),*(), 席彪2), 房立华3), 吕坚4), 王甘娇4), 张潇1)
收稿日期:2022-02-28
修回日期:2022-05-09
出版日期:2022-12-20
发布日期:2023-01-21
通讯作者:
盛书中
作者简介:张苏祥, 男, 1997年生, 2020年于防灾科技学院获地球物理学专业学士学位, 现为东华理工大学地球物理学专业在读硕士研究生, 主要从事发震构造和构造应力场等方面研究, E-mail: zhangsuxiang@ecut.edu.cn。
基金资助:
ZHANG Su-xiang1)(), SHENG Shu-zhong1),*(), XI Biao2), FANG Li-hua3), LÜ Jian4), WANG Gan-jiao4), ZHANG Xiao1)
Received:2022-02-28
Revised:2022-05-09
Online:2022-12-20
Published:2023-01-21
Contact:
SHENG Shu-zhong
摘要:
为实现根据地震空间分布自动识别断层和获取断层参数, 文中提出基于改进的DBSCAN算法自动识别断层的方法。该方法首先根据数据集的特性对无监督聚类技术(DBSCAN)进行改进, 实现自动选择聚类最优参数和断层段识别; 其次, 对识别出的断层段采用模拟退火全局搜索-高斯牛顿局部搜索结合法计算其断层参数, 再对邻近的相似断层段进行合并, 最终给出基于地震空间分布识别出的断层及其参数。文中采用人工合成数据验证了上述方法的可靠性, 并将其应用于唐山地区, 获得以下结果: 1)人工合成数据和唐山地区双差定位数据验证了本研究改进的DBSCAN算法可以自动识别断层。2)基于唐山地区双差精定位地震数据, 本研究自动识别出8个断裂段: 陡河断裂段、 巍山-丰南断裂段、 滦县-乐亭断裂段、 卢龙断裂段、 徐家楼-王喜庄断裂段、 滦县断裂北段、 雷庄断裂段和陈官屯断裂段。其中, 前5个断裂段的识别结果与前人研究结果基本一致; 后3条断裂段为文中基于地震目录新识别出的断层。可见, 文中给出的方法可自动化识别断层并获取断层参数, 这为断裂构造的识别提供了新的思路和方法。
中图分类号:
张苏祥, 盛书中, 席彪, 房立华, 吕坚, 王甘娇, 张潇. 基于改进的DBSCAN算法自动识别断层方法研究及其在唐山地区的应用[J]. 地震地质, 2022, 44(6): 1615-1633.
ZHANG Su-xiang, SHENG Shu-zhong, XI Biao, FANG Li-hua, LÜ Jian, WANG Gan-jiao, ZHANG Xiao. AUTOMATIC FAULT IDENTIFICATION METHOD BASED ON IMPROVED DBSCAN ALGORITHM AND ITS APPLICATION TO TANGSHAN AREA[J]. SEISMOLOGY AND GEOLOGY, 2022, 44(6): 1615-1633.
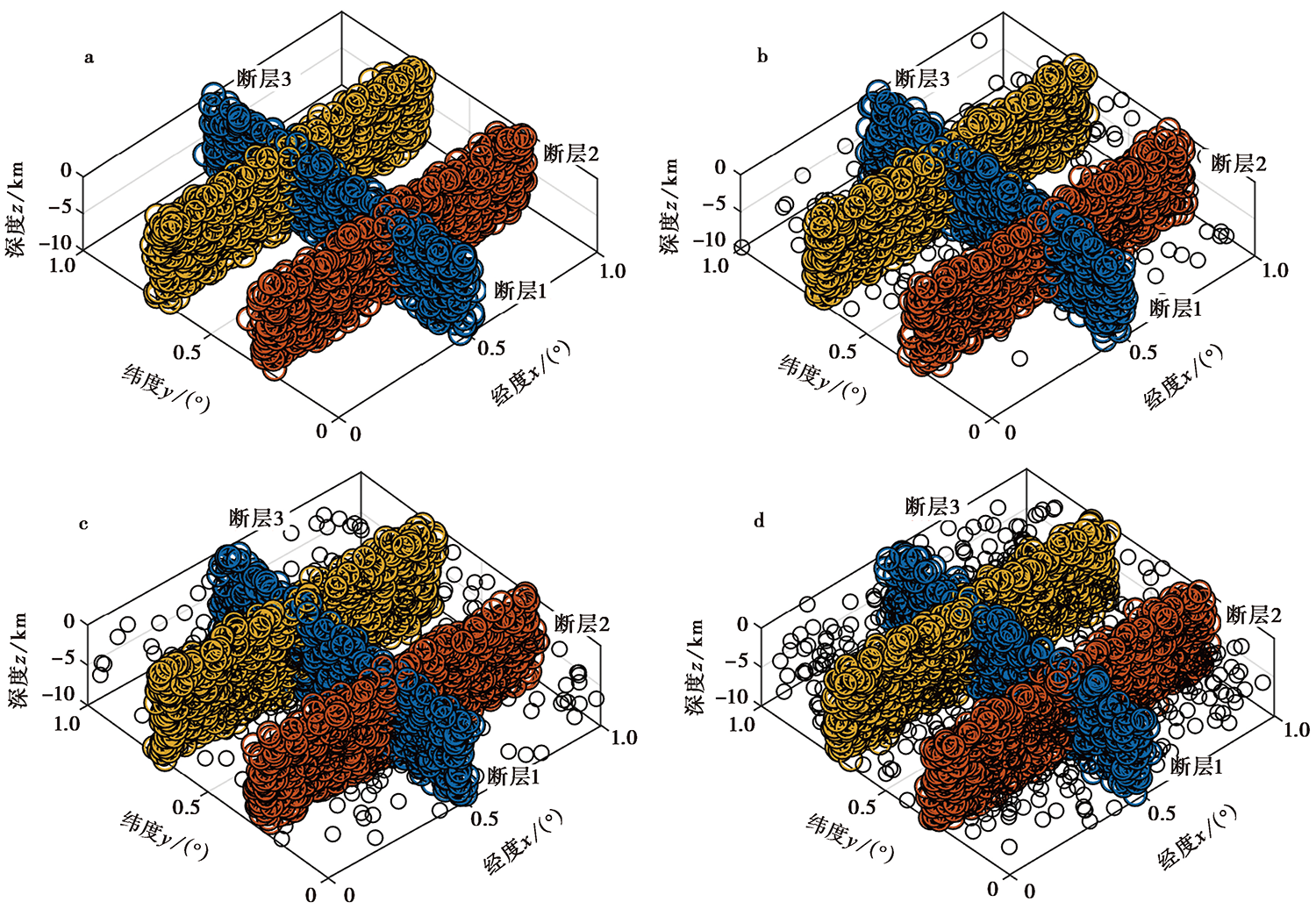
图 1 a 人工合成地震数据; b-d 分别添加总地震事件5%、 10%和20%随机地震后的地震空间分布图 黑色圆圈表示随机地震(即噪声), 其余为断层上的地震事件
Fig. 1 The spatial distribution of synthetic seismic data(a) and adding random earthquakes which account for 5%, 10% and 20% of total seismic events(b-d), respectively.
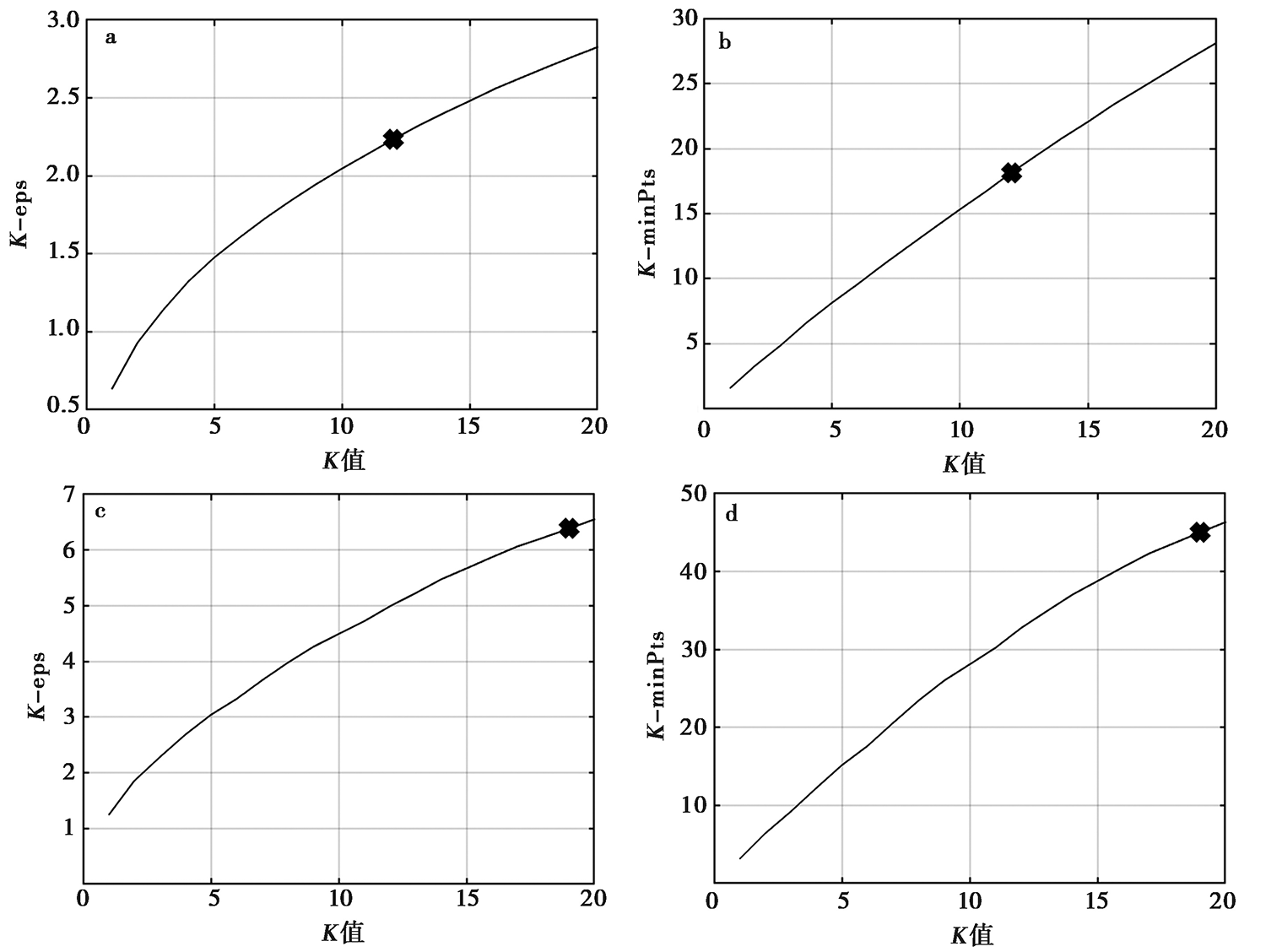
图 2 添加5%噪声的合成断层数据第1次聚类(a、 b)和第2次聚类(c、 d)的K-eps、 K-minPts关系图 标记处为最优参数
Fig. 2 K-eps, K-minPts diagrams of first clustering(a, b) and second clustering(c, d) for synthetic data with 5% noise.
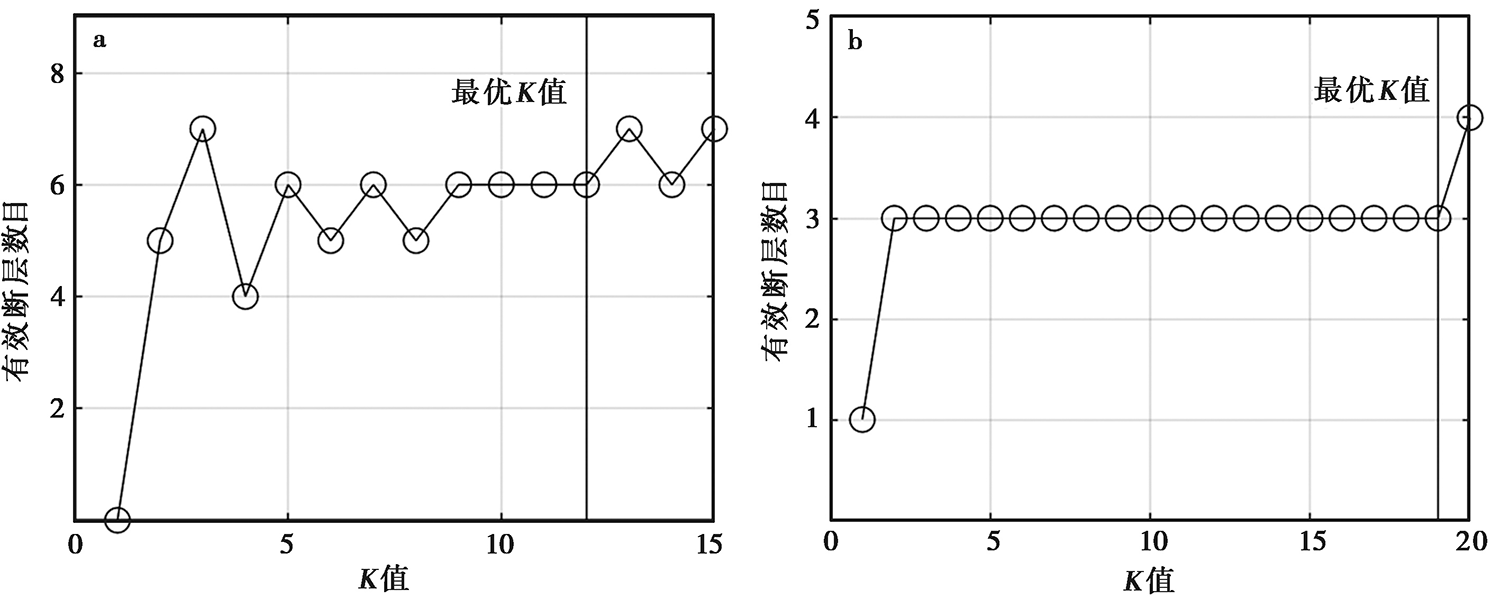
图 3 添加5%噪声的合成数据第1次聚类(a)和第2次聚类(b)的K值与有效断层数目关系图
Fig. 3 K-number of effective faults diagram of first clustering(a) and second clustering(b) for synthetic data with 5% noise.
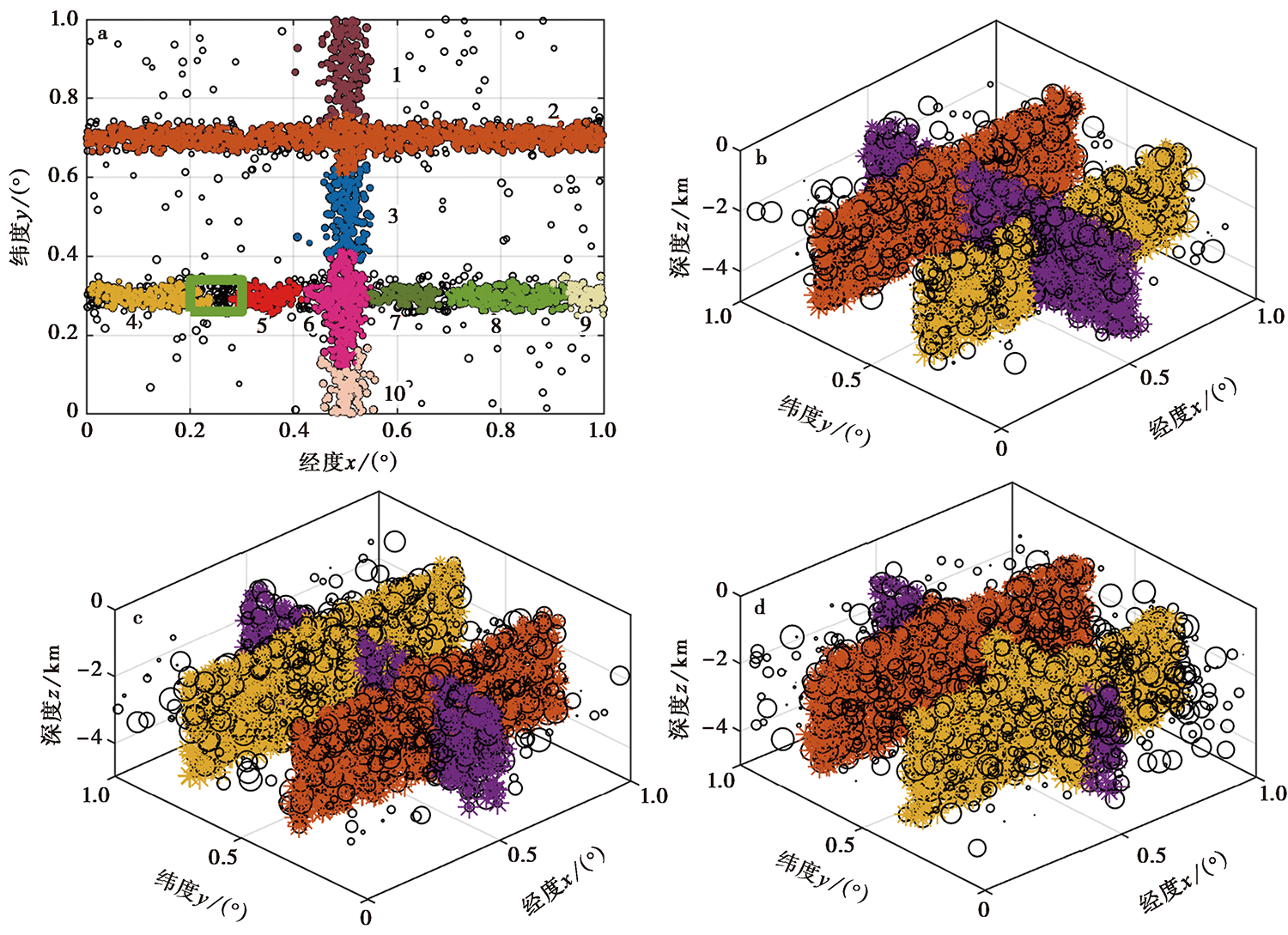
图 4 添加噪声数据自动识别断层面的结果 a 添加5%噪声的合成数据未合并的识别结果, 矩形框为最小事件数阈值选取区域; b 添加5%噪声的合成数据断层面合并后的识别结果; c 添加10%噪声的合成数据断层面合并后的识别结果; d 添加20%噪声的合成数据断层面合并后的识别结果; 用不同颜色标示识别出的断层段
Fig. 4 Automatic fault plane recognition results for synthetic data.
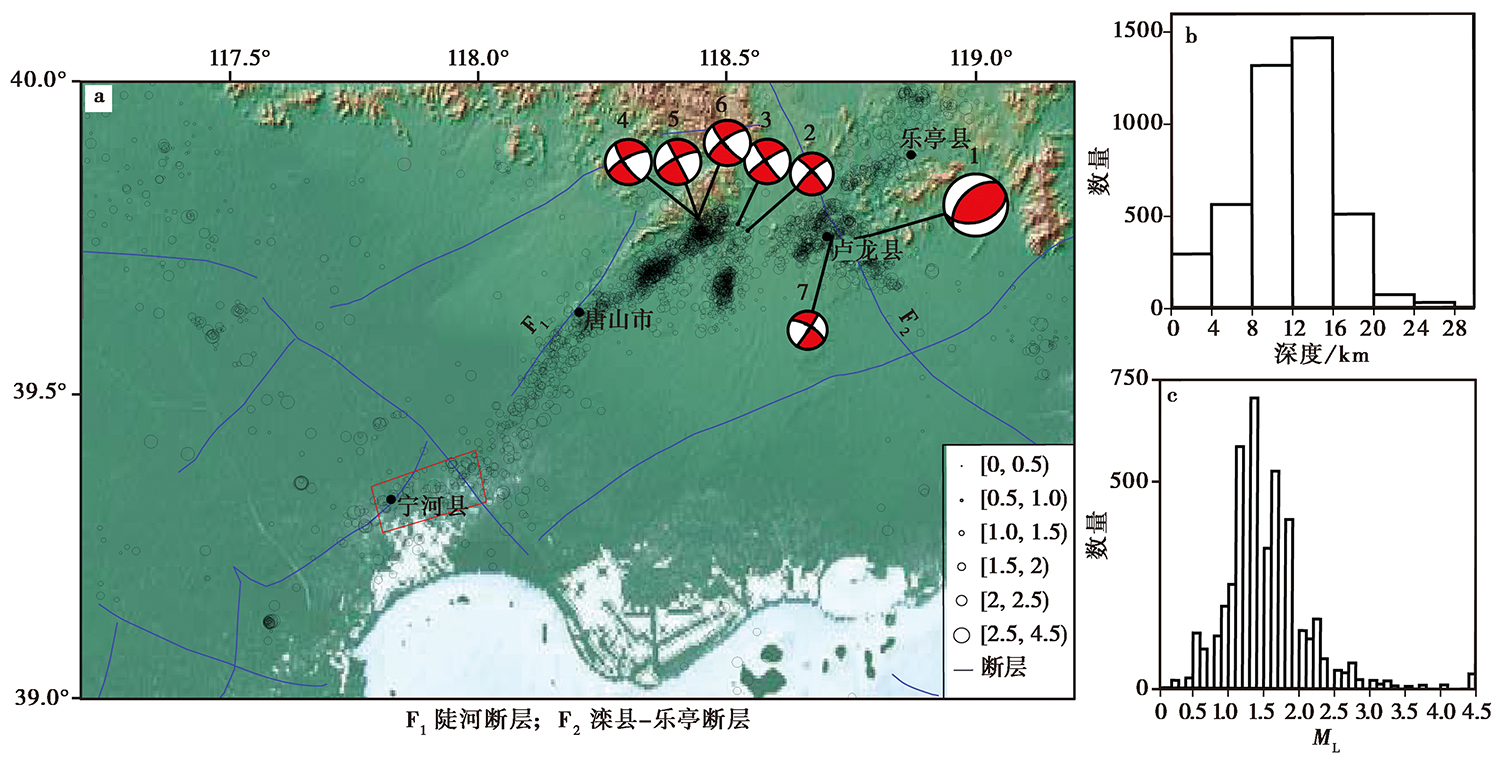
图 5 唐山地震序列的震中(a)、 深度(b)和震级(c)分布图 矩形框为最小事件数阈值的选取区域
Fig. 5 Distribution of epicenter(a), depth(b)and magnitude(c) of the Tangshan earthquake sequence, China.
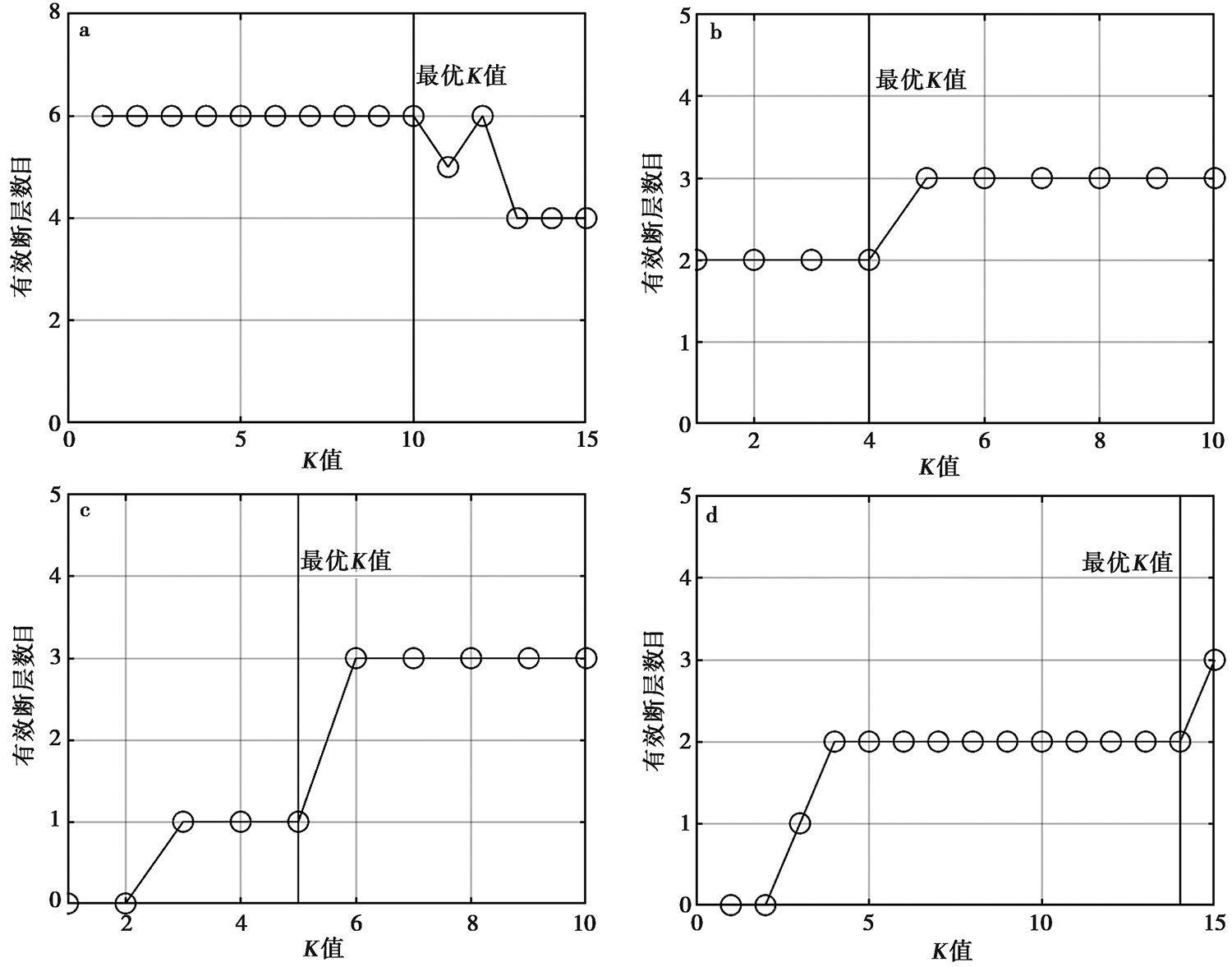
图 6 唐山地区4层密度聚类的K值与有效断层数目的关系图(a-d)
Fig. 6 Relationship between K value of four-level density clustering and the number of effective faults in Tangshan area(a-d).
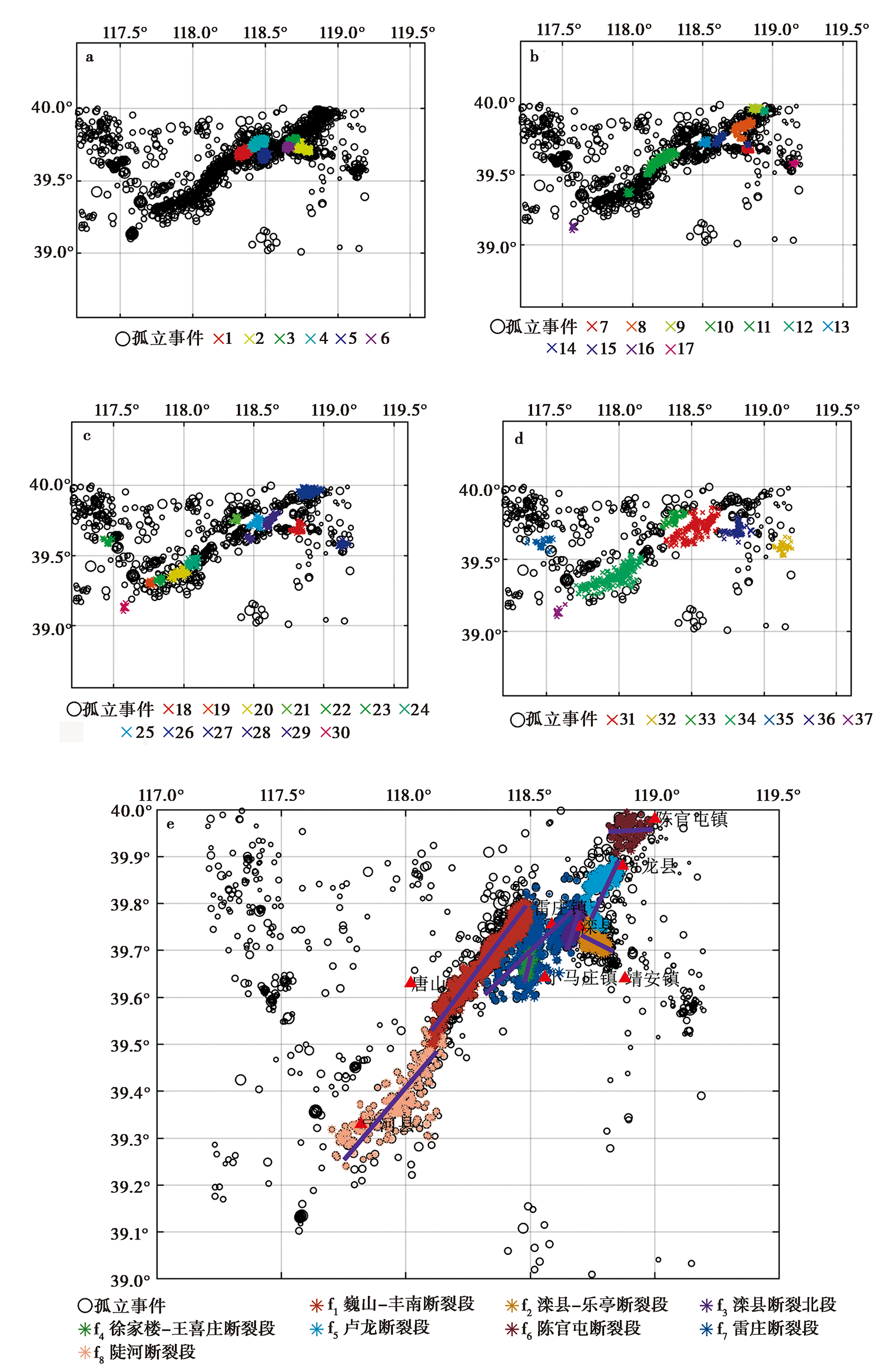
图 7 唐山地区第1、 2、 3、 4次聚类结果图(a-d)和最终断层识别结果图(e)
Fig. 7 Graph of the first, second, third and fourth clustering results(a-d) and final fault identification results(e)in Tangshan area.
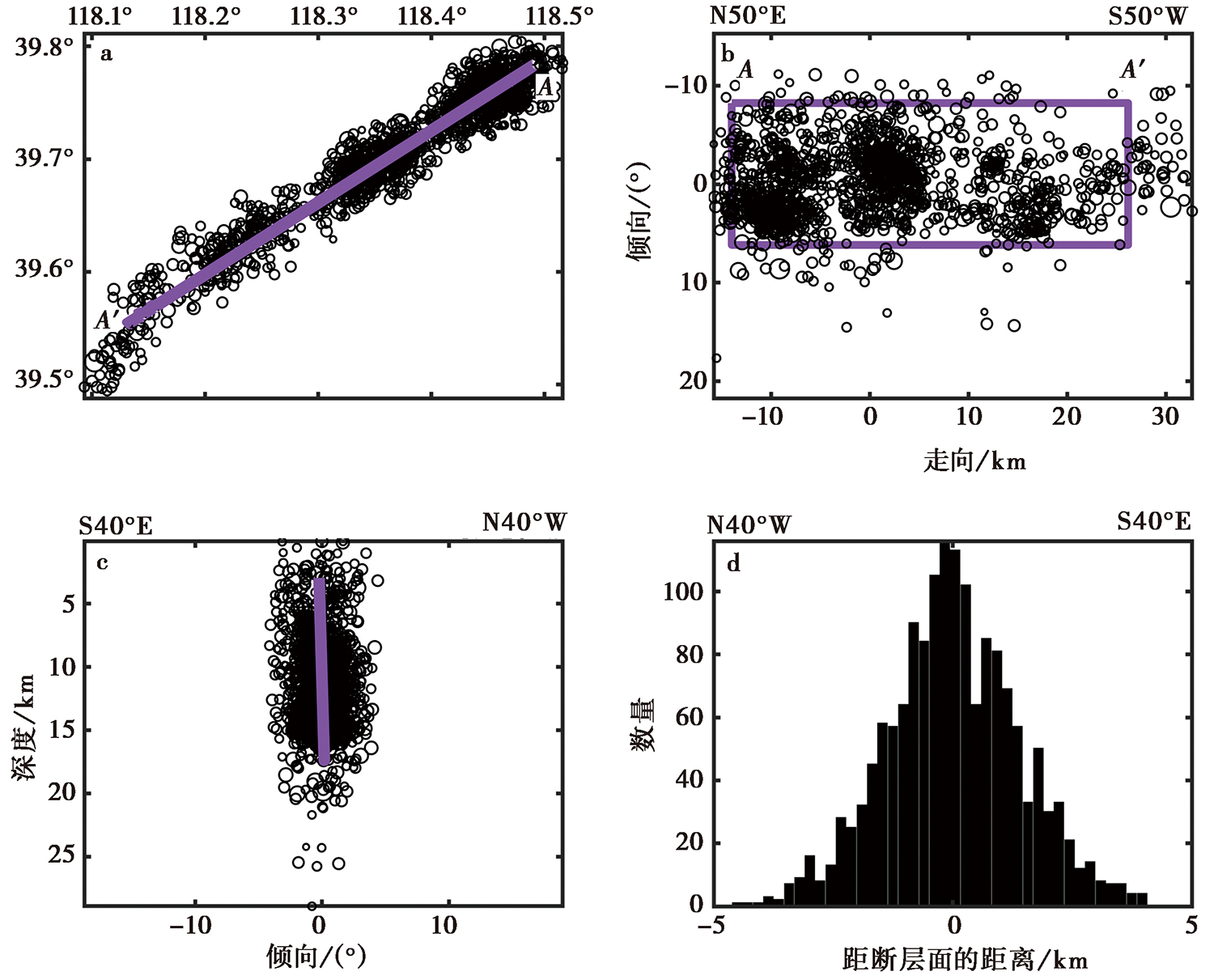
图 8 巍山-丰南断裂段(f1)的小地震拟合结果 a 小地震的水平面投影; b 小地震的断层面投影; c 小地震垂直于断层面的横断面投影; d 小地震与断层面的距离
Fig. 8 The fitting result by using small earthquakes of Weishan-Fengnan Fault(f1).
| 断层符号 | 断层名 | 小地震 个数 | 走向/(°) | 倾角/(°) | 数据来源 | ||
|---|---|---|---|---|---|---|---|
| 值 | 标准差 | 值 | 标准差 | ||||
| f1 | 巍山-丰南断裂段 | 1559 | 230.4 | 0.003 | 88.4 | 0.01 | 本文结果 |
| f2 | 滦县-乐亭断裂段 | 506 | 132.2 | 0.03 | 89.3 | 0.02 | 本文结果 |
| 160 | 118.4 | 1.9 | 76.9 | 2.0 | 万永革等, | ||
| 404 | 125.1 | 1.6 | 76.2 | 1.8 | 胡晓辉等, | ||
| f3 | 滦县断裂北段 | 336 | 31.0 | 0.02 | 88.2 | 0.01 | 本文结果 |
| f4 | 徐家楼-王喜庄断裂段 | 351 | 191.3 | 0.03 | 88.4 | 0.01 | 本文结果 |
| f5 | 卢龙断裂段 | 243 | 31.7 | 0.04 | 88.6 | 0.03 | 本文结果 |
| 176 | 39.0 | 0.9 | 86.7 | 1.3 | 万永革等, | ||
| 694 | 46.1 | 0.6 | 89.3 | 1.5 | 胡晓辉等, | ||
| f6 | 陈官屯断裂段 | 144 | 84.9 | 0.06 | 85.4 | 0.04 | 本文结果 |
| f7 | 雷庄断裂段 | 244 | 229.5 | 0.03 | 73.8 | 0.04 | 本文结果 |
| f8 | 陡河断裂段 | 225 | 229.1 | 0.03 | 51.6 | 0.06 | 本文结果 |
| 61 | 253.3 | 3.9 | 66.0 | 5.0 | 万永革等, | ||
| 33 | 246.6 | 4.0 | 81.8 | 4.2 | 胡晓辉等, |
表1 利用本文方法求得的唐山地区各段断层面的走向、 倾角和标准差
Table1 Fault plane parameters of Tangshan region obtained by using the automatic fault identification method
| 断层符号 | 断层名 | 小地震 个数 | 走向/(°) | 倾角/(°) | 数据来源 | ||
|---|---|---|---|---|---|---|---|
| 值 | 标准差 | 值 | 标准差 | ||||
| f1 | 巍山-丰南断裂段 | 1559 | 230.4 | 0.003 | 88.4 | 0.01 | 本文结果 |
| f2 | 滦县-乐亭断裂段 | 506 | 132.2 | 0.03 | 89.3 | 0.02 | 本文结果 |
| 160 | 118.4 | 1.9 | 76.9 | 2.0 | 万永革等, | ||
| 404 | 125.1 | 1.6 | 76.2 | 1.8 | 胡晓辉等, | ||
| f3 | 滦县断裂北段 | 336 | 31.0 | 0.02 | 88.2 | 0.01 | 本文结果 |
| f4 | 徐家楼-王喜庄断裂段 | 351 | 191.3 | 0.03 | 88.4 | 0.01 | 本文结果 |
| f5 | 卢龙断裂段 | 243 | 31.7 | 0.04 | 88.6 | 0.03 | 本文结果 |
| 176 | 39.0 | 0.9 | 86.7 | 1.3 | 万永革等, | ||
| 694 | 46.1 | 0.6 | 89.3 | 1.5 | 胡晓辉等, | ||
| f6 | 陈官屯断裂段 | 144 | 84.9 | 0.06 | 85.4 | 0.04 | 本文结果 |
| f7 | 雷庄断裂段 | 244 | 229.5 | 0.03 | 73.8 | 0.04 | 本文结果 |
| f8 | 陡河断裂段 | 225 | 229.1 | 0.03 | 51.6 | 0.06 | 本文结果 |
| 61 | 253.3 | 3.9 | 66.0 | 5.0 | 万永革等, | ||
| 33 | 246.6 | 4.0 | 81.8 | 4.2 | 胡晓辉等, |
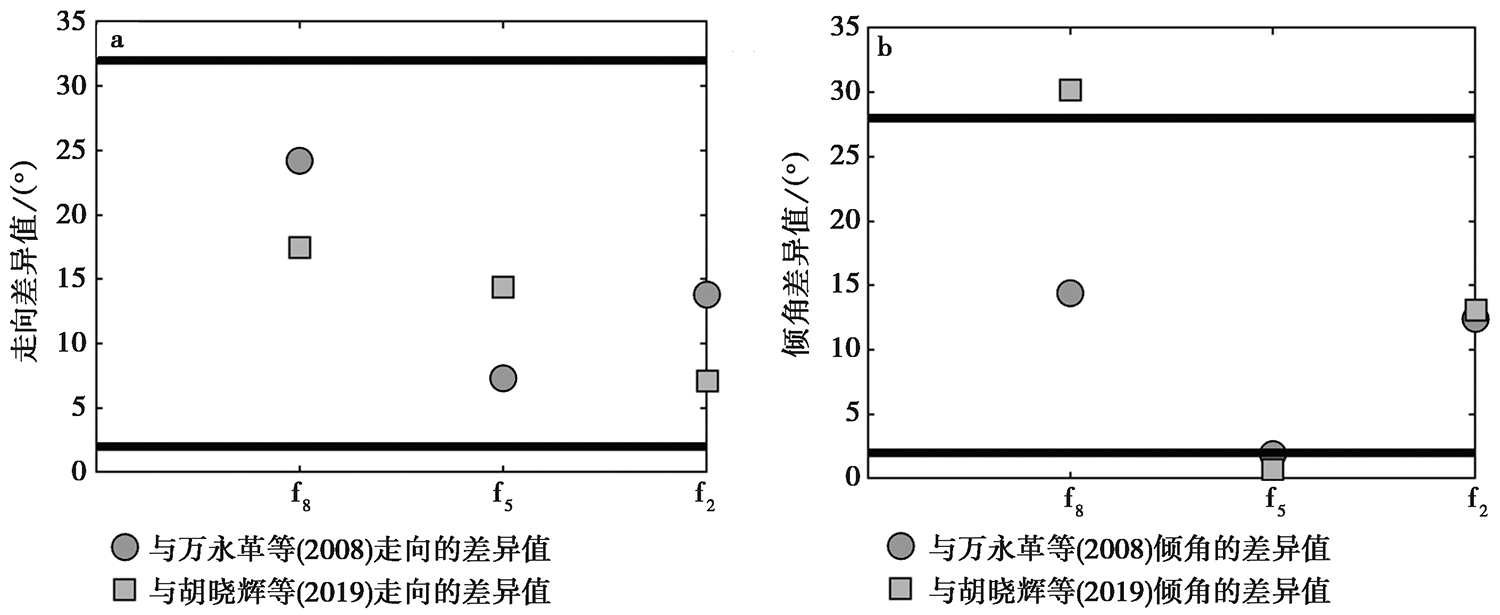
图 9 本文结果与前人研究结果走向(a)和倾角(b)的差异值 线段为胡晓辉等(2019)总结的断层参数差异范围
Fig. 9 Difference of fault strike(a)and dip(b)between the results of this paper and those of previous studies.
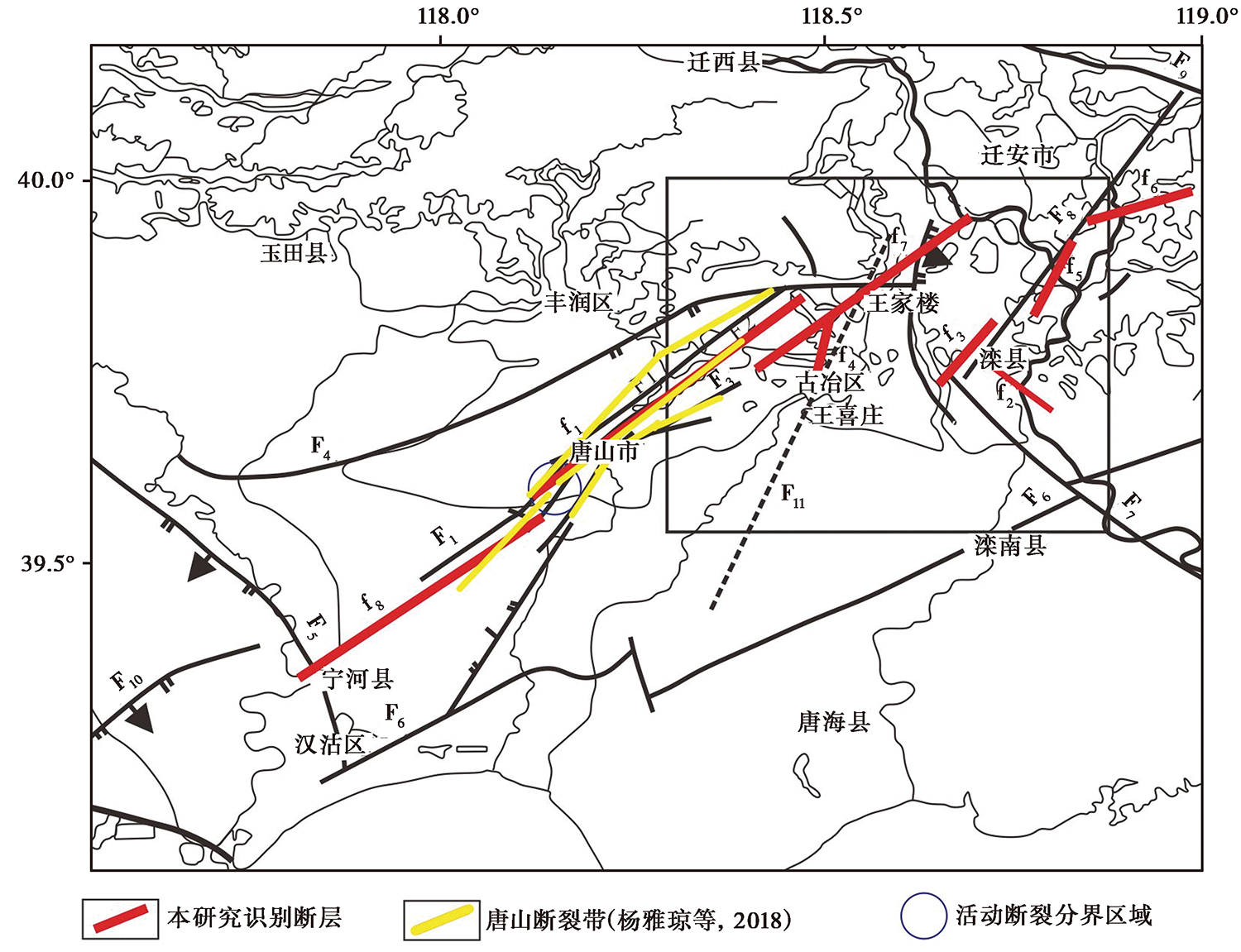
图 10 唐山地区的主要断层分布图(刘亢等, 2015) F1陡河断层; F2巍山-丰南断层; F3古冶-南湖断层; F4丰台-野鸡坨断层; F5蓟运河断层; F6宁河-昌黎断层; F7滦县-乐亭断层; F8卢龙断层; F9建昌营断层; F10沧东断层; F11徐家楼-王喜庄断层
Fig. 10 Distribution of major faults in Tangshan area(after LIU Kang et al., 2015).
| 序号 | 日期 | 东经 /(°) | 北纬 /(°) | 震级 /MW | 震源 深度 /km | 走向 /(°) | 倾角 /(°) | 滑动角 /(°) | 所属断层 | 数据来源 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1976-07-28 | 118.78 | 39.75 | 7.0 | 15.0 | 72 | 44 | -110 | 卢龙断裂段 | GCMT |
| 2 | 2012-05-28 | 118.54 | 39.76 | 4.7 | 23.5 | 227 | 80 | 172 | 雷庄断裂段 | GCMT |
| 3 | 2020-07-11 | 118.52 | 39.77 | 5.0 | 23.0 | 236 | 81 | -175 | 雷庄断裂段 | GCMT |
| 4 | 2020-07-12 | 118.44 | 39.78 | 5.1 | 10.0 | 241 | 73 | -164 | 巍山-丰南断裂段 | 中国地震局地球物理研究所* |
| 5 | 2020-07-12 | 118.44 | 39.78 | 5.1 | 10.0 | 243 | 75 | -180 | 巍山-丰南断裂段 | 郭祥云等* |
| 6 | 2020-07-12 | 118.44 | 39.78 | 5.1 | 10.0 | 234 | 73 | -168 | 巍山-丰南断裂段 | 梁珊珊等* |
| 7 | 2021-04-16 | 118.71 | 39.75 | 4.3 | 9.0 | 302 | 70 | -3 | 滦县-乐亭断裂段 | 河北省地震局* |
表2 震源机制解目录
Table2 Catalog of focal mechanism
| 序号 | 日期 | 东经 /(°) | 北纬 /(°) | 震级 /MW | 震源 深度 /km | 走向 /(°) | 倾角 /(°) | 滑动角 /(°) | 所属断层 | 数据来源 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1976-07-28 | 118.78 | 39.75 | 7.0 | 15.0 | 72 | 44 | -110 | 卢龙断裂段 | GCMT |
| 2 | 2012-05-28 | 118.54 | 39.76 | 4.7 | 23.5 | 227 | 80 | 172 | 雷庄断裂段 | GCMT |
| 3 | 2020-07-11 | 118.52 | 39.77 | 5.0 | 23.0 | 236 | 81 | -175 | 雷庄断裂段 | GCMT |
| 4 | 2020-07-12 | 118.44 | 39.78 | 5.1 | 10.0 | 241 | 73 | -164 | 巍山-丰南断裂段 | 中国地震局地球物理研究所* |
| 5 | 2020-07-12 | 118.44 | 39.78 | 5.1 | 10.0 | 243 | 75 | -180 | 巍山-丰南断裂段 | 郭祥云等* |
| 6 | 2020-07-12 | 118.44 | 39.78 | 5.1 | 10.0 | 234 | 73 | -168 | 巍山-丰南断裂段 | 梁珊珊等* |
| 7 | 2021-04-16 | 118.71 | 39.75 | 4.3 | 9.0 | 302 | 70 | -3 | 滦县-乐亭断裂段 | 河北省地震局* |
| [1] | 杜晨晓, 谢富仁, 张扬, 等. 2010. 1976年 MS7.8 唐山地震断层动态破裂及近断层强地面运动特征[J]. 地球物理学报, 53(2): 290-304. |
| DU Chen-xiao, XIE Fu-ren, ZHANG Yang, et al. 2010. 3D modeling of dynamic fault rupture and strong ground motion of the 1976 MS7.8 Tangshan earthquake[J]. Chinese Journal of Geophysics, 53(2): 290-304. (in Chinese) | |
| [2] | 付泽强, 王晓锋. 2018. 基于变参数的DBSCAN算法[J]. 网络安全技术与应用, 212(8): 37-39. |
| FU Ze-qiang, WANG Xiao-feng. 2018. DBSCAN algorithm based on variable parameters[J]. Network Security Technology and Application, 212(8): 37-39. (in Chinese) | |
| [3] | 高彬, 周仕勇, 蒋长胜. 2016. 基于地震活动性资料估计鄂尔多斯块体周缘构造断层面倾角[J]. 地球物理学报, 59(7): 2444-2452. |
| GAO Bin, ZHOU Shi-yong, JIANG Chang-sheng. 2016. Estimate of dip angles of faults around Ordos Block based on earthquakes[J]. Chinese Journal of Geophysics, 59(7): 2444-2452. (in Chinese) | |
| [4] | 侯雄文. 2017a. 浅析DBSCAN算法中参数设置问题的研究[J]. 科教导刊(电子版), (30): 266-267. |
| HOU Xiong-wen. 2017a. Study on parameters setting in DBSCAN algorithm[J]. The Guide of Science & Education(Electronic Edition), (30): 266-267. (in Chinese) | |
| [5] | 侯雄文. 2017b. 浅析DBSCAN算法中参数设置问题的研究[EB/OL].(2017-10-30)[2021-9-10]. http://www.cqvip.com/main/viewer.aspx?id=673919599&type=5&sign=34410979c32d75c45fee9e654591182f&view=1. |
| HOU Xiong-wen. 2017b. Study on parameters setting in DBSCAN algorithm[EB/OL].(2017-10-30)[2021-9-10]. http://www.cqvip.com/main/viewer.aspx?id=673919599&type=5&sign=34410979c32d75c45fee9e654591 182f&view=1. | |
| [6] | 胡晓辉, 盛书中, 万永革, 等. 2019. 基于国家地震科学数据开展断层面参数研究的初探: 以唐山地震为例[J]. 震灾防御技术, 14(2): 341-351. |
| HU Xiao-hui, SHENG Shu-zhong, WAN Yong-ge, et al. 2019. Preliminary study on fault parameters based on national seismic data: An example of Tangshan earthquake[J]. Earthquake Disaster Prevention Technology, 14(2): 341-351. (in Chinese) | |
| [7] | 黄文辉, 康英, 苏柱金, 等. 2016. 全国统一编目系统设计与实现[J]. 地震地磁观测与研究, 37(4): 170-175. |
| HUANG Wen-hui, KANG Ying, SU Zhu-jin, et al. 2016. The design and implementation of unified national cataloging system[J]. Seismological and Geomagnetic Observation and Research, 37(4): 170-175. (in Chinese) | |
| [8] | 李钦祖, 张之立, 靳雅敏, 等. 1980. 唐山地震的震源机制[J]. 地震地质, 2(4): 59-67. |
| LI Qin-zu, ZHANG Zhi-li, JIN Ya-min, et al. 1980. Focal mechanism of the Tangshan earthquake[J]. Seismology and Geology, 2(4): 59-67. (in Chinese) | |
| [9] |
李文杰, 闫世强, 蒋莹, 等. 2019. 自适应确定DBSCAN算法参数的算法研究[J]. 计算机工程与应用, 55(5): 1-7.
DOI |
|
LI Wen-jie, YAN Shi-qiang, JIANG Ying, et al. 2019. Research on method of self-adaptive determination of DBSCAN algorithm parameters[J]. Computer Engineering and Applications, 55(5): 1-7. (in Chinese)
DOI |
|
| [10] | 刘亢, 曲国胜, 房立华, 等. 2015. 唐山古冶、 滦县地区中小地震活动与构造关系研究[J]. 地震, 35(2): 111-120. |
| LIU Kang, QU Guo-sheng, FANG Li-hua, et al. 2015. Relationship between tectonics and small to moderate earthquakes in Guye and Luanxian area, Hebei Province[J]. Earthquake, 35(2): 111-120. (in Chinese) | |
| [11] | 盛书中. 2015. 鄂尔多斯块体周缘地壳应力场与断层面参数的研究[D]. 北京: 中国地震局地球物理研究所:67-69. |
| SHENG Shu-zhong. 2015. Study on the crustal stress field and the fault plane parameter of circum-Ordos block region[D]. Institute of Geophysics, China Earthquake Administration, Beijing: 67-69. (in Chinese) | |
| [12] | 盛书中, 万永革, 蒋长胜, 等. 2015. 2015年尼泊尔 MS8.1 强震对中国大陆静态应力触发影响的初探[J]. 地球物理学报, 58(5): 1834-1842. |
| SHENG Shu-zhong, WAN Yong-ge, JIANG Chang-sheng, et al. 2015. Preliminary study on the static stress triggering effects on China mainland with the 2015 Nepal MS8.1 earthquake[J]. China Journal of Geophysics, 58(5): 1834-1842. (in Chinese) | |
| [13] | 盛书中, 万永革, 王未来, 等. 2014. 2010年玉树 MS7.1 地震发震断层面参数的确定[J]. 地球物理学进展, 29(4): 1555-1562. |
| SHENG Shu-zhong, WAN Yong-ge, WANG Wei-lai, et al. 2014. The determination of seismogenic fault plane parameters of Yushu MS7.1 earthquake in 2010[J]. Progress in Geophysics, 29(4): 1555-1562. (in Chinese) | |
| [14] | 万永革, 沈正康, 刁桂苓, 等. 2008. 利用小震分布和区域应力场确定大震断层面参数方法及其在唐山地震序列中的应用[J]. 地球物理学报, 51(3): 793-804. |
| WAN Yong-ge, SHEN Zheng-kang, DIAO Gui-ling, et al. 2008. An algorithm of fault parameter determination using distribution of small earthquakes and parameters of regional stress field and its application to Tangshan earthquake sequence[J]. China Journal of Geophysics, 51(3): 793-804. (in Chinese) | |
| [15] | 杨雅琼, 冯向东, 刁桂苓, 等. 2018. 震源断层方法在活断层探测中的应用[J]. 灾害学, 33(2): 70-75. |
| YANG Ya-qiong, FENG Xiang-dong, DIAO Gui-ling, et al. 2018. The application of seismogenic fault method in active fault detection[J]. Journal of Catastrophology, 33(2): 70-75. (in Chinese) | |
| [16] | 杨雅琼, 王晓山, 万永革, 等. 2016. 由震源机制解推断唐山地震序列发震断层的分段特征[J]. 地震学报, 38(4): 632-643. |
| YANG Ya-qiong, WANG Xiao-shan, WAN Yong-ge, et al. 2016. Seismogenic fault segmentation of Tangshan earthquake sequence derived from focal mechanism solutions[J]. Acta Seismologica Sinica, 38(4): 632-643. (in Chinese) | |
| [17] | 曾宪伟, 闻学泽, 龙锋. 2019. 由初至P震相重新定位2017年九寨沟地震序列的主震与ML≥3.0余震并分析发震构造[J]. 地球物理学报, 62(12): 4604-4619. |
| ZENG Xian-wei, WEN Xue-ze, LONG Feng. 2019. Relocating the mainshock and ML≥3.0 aftershocks of the 2017 Jiuzhaigou sequence using first arriving P-phase only and reanalyzing the seismogenic structure [J]. Chinese Journal of Geophysics, 62(12): 4604-4619 (in Chinese) | |
| [18] |
张培震, 朱守彪, 张竹琪, 等. 2012. 汶川地震的发震构造与破裂机理[J]. 地震地质, 34(4): 566-575. doi: 10.3969/j.issn.0253-4967.2012.04.003.
DOI |
| ZHANG Pei-zhen, ZHU Shou-biao, ZHANG Zhu-qi, et al. 2012. Seismogenic structure and rupture mechanism of the MS8.0 Wenchuan earthquake[J]. Seismology and Geology, 34(4): 566-575. (in Chinese) | |
| [19] | 张泽明, 丁慧霞, 董昕, 等. 2021. 俯冲带变质作用与构造机制[J]. 岩石学报, 37(11): 3377-3398. |
|
ZHANG Ze-ming, DING Hui-xia, DONG Xin, et al. 2021. Metamorphism and tectonic mechanisms of subduction zones[J]. Acta Petrologica Sinica, 37(11): 3377-3398. (in Chinese)
DOI URL |
|
| [20] | 张之立, 李钦祖, 谷继成, 等. 1980. 唐山地震的破裂过程及其力学分析[J]. 地震学报, 2(2): 111-129. |
| ZHANG Zhi-li, LI Qin-zu, GU Ji-cheng, et al. 1980. Rupture process and mechanical analysis of Tangshan earthquake[J]. Acta Seismologica Sinica, 2(2): 111-129. (in Chinese) | |
| [21] |
Brunsvik B, Morra G, Cambiotti G, et al. 2021. Three-dimensional Paganica fault morphology obtained from hypocenter clustering(L'Aquila 2009 seismic sequence, Central Italy)[J]. Tectonophysics, 804: 228756.
DOI URL |
| [22] | Chang C C, Lin C J. 2011. Libsvm: A library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2(3): 1-27. |
| [23] | Ester M, Kriegel H P, Sander J, et al. 1996. International conference on knowledge discovery & data mining[C]. United States: Association for the Advancement of Artificial Intelligence. |
| [24] |
Guyon I, Jason W, Stephen B. 2002. Gene selection for cancer classification using support vector machines[J]. Machine Learning, 46(1-3): 389-422.
DOI URL |
| [25] |
Hayes G P, Wald D J. 2010. Developing framework to constrain the geometry of the seismic rupture plane on subduction interfaces a priori: A probabilistic approach[J]. Geophysical Journal International, 176(3): 951-964.
DOI URL |
| [26] | Kamer Y, Ouillon G, Sornette D. 2020. Fault network reconstruction using agglomerative clustering: Applications to southern Californian seismicity[J]. Natural Hazards and Earth System Sciences, 20(12): 3611-3625. |
| [27] |
Markou M T, Kassomenos P. 2010. Cluster analysis of five years of back trajectories arriving in Athens, Greece[J]. Atmospheric Research, 98(2-4): 438-457.
DOI URL |
| [28] | Ouillon G, Ducorbier C, Sornette D. 2008. Automatic reconstruction of fault networks from seismicity catalogs: Three-dimensional optimal anisotropic dynamic clustering[J]. Journal of Geophysical Research, 113(B1): B01306. |
| [29] |
Scitovski S. 2017. A density-based clustering algorithm for earthquake zoning[J]. Computers & Geosciences, 110: 90-95.
DOI URL |
| [30] |
Shang X Y, Li X, Antonio M E, et al. 2018. Data field-based K-Means clustering for spatio-temporal seismicity analysis and hazard assessment[J]. Remote Sensing, 10(3): 461.
DOI URL |
| [31] | Skoumal R J, Kaven J O, Walter J I. 2019. Characterizing seismogenic fault structures in Oklahoma using a relocated template-matched catalog[J]. Seismological Research Letters, 90(4): 1539-1543. |
| [32] |
Wang Y, Ouillon G, Woessner J, et al. 2013. Automatic reconstruction of fault networks from seismicity catalogs including location uncertainty[J]. Journal of Geophysical Research: Solid Earth, 118(11): 5956-5975.
DOI URL |
| [33] |
Wessel P, Smith W. 1998. New, improved version of generic mapping tools released[J]. Eos Transactions American Geophysical Union, 79(47): 579.
DOI URL |
| [1] | 齐文华, 苏桂武, 张素灵, 刘新圣, 魏本勇, 孙磊. 城市化过程中房屋地震灾害脆弱性和损失风险变化研究——以唐山市区及城乡过渡乡镇为例[J]. 地震地质, 2012, (4): 820-834. |
| [2] | 谢觉民, 黄立人. 唐山地震前后的地壳垂直运动[J]. 地震地质, 1987, 9(3): 1-19. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
